Even amongst practitioners, there is no truly well accepted definition for machine learning. So, I’ll provide two:
- Pioneer machine learning researcher Arthur Samuel defined machine learning as: “the field of study that gives computers the ability to learn without being explicitly programmed”. This definition is beautiful in its simplicity though lacks a little formality. So, with a little more structure,..
- Tom Mitchell states that “a computer program is said to learn from experience E, with respect to some task T, and some performance measure P, if its performance on T as measured by P improves with experience E”.
Let’s reinforce the definitions with an example. A classic practical application is the email spam filter. The email program watches which emails the user does or does not mark as spam and, based on that, learns how to better filter future spam automatically. In the parlance of Tim Mitchell’s definition, classifying the emails as spam or not span is the task, T, watching the user label emails as spam or not spam is the experience, E, and the fraction emails correctly classified could be the perform measure, P.
There are a great number of machine learning algorithms and, as such, they are often divided into three main types: supervised, unsupervised and reinforcement learning algorithms.
Supervised Learning – machine learning with labels
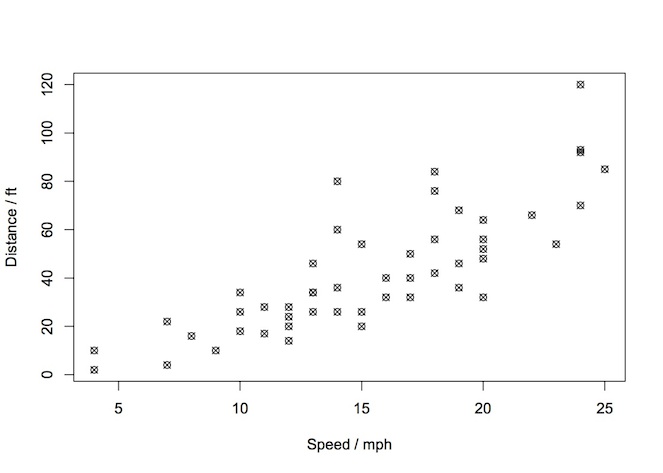
Before providing a definition, let’s start with an example. Imagine you want to predict the stopping distance for cars given the speed that the car is travelling. The graph below shows some data from the “cars” dataset in R.
A supervised learning algorithm would allow us to use the data available to make a general rule for making predictions about future distances for speeds that we have not yet witnessed. In our two-variable example, this is the well-know task of fitting a line to the data. Eyeballing the data, we could conceivably fit a linear model (red) or a polynomial model (blue) shown below.
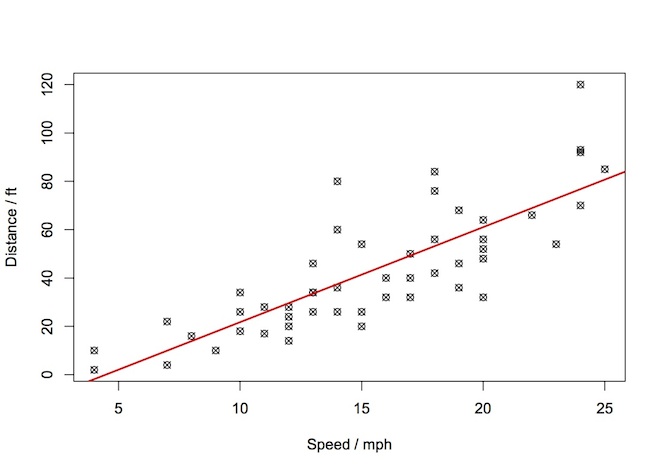
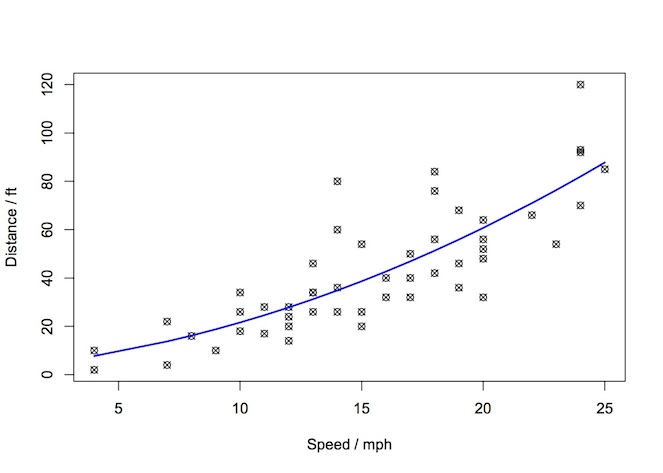
Fitting these models is an example of a supervised learning algorithm. The term supervised learning refers to the fact the algorithm requires a dataset for training that contain the “right” answers. That is to say, in our example, for every datapoint on the cars speed, we also had the corresponding data for the actual stopping distance.
The cars example is also a case of a regression problem, where we are predicting a continuous valued output (the distance).
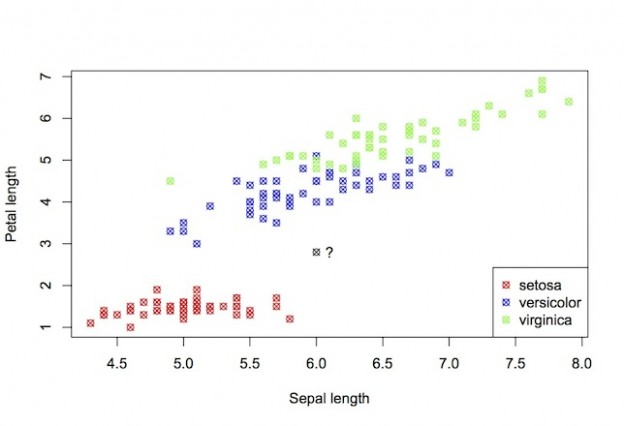
Another type of supervised learning task is classification. Again, let’s set the scene with an example.
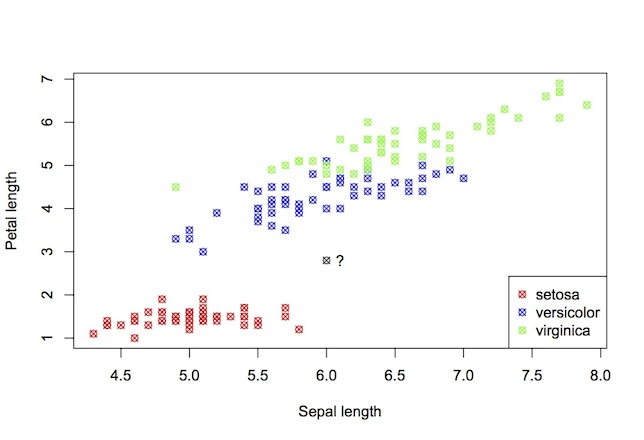
The figure above shows data from the well-known iris database. It shows a scatter plot of the sepal length vs. petal length of a number of iris plants. The points are coloured by species. Here, the machine learning task is to predict the species given new petal and sepal measurements. Which species would you label the new data-point in black? What makes this a classification task is that the variable to be predicted (species) is discrete valued.
Unsupervised Learning – machine learning without labels
With unsupervised learning, the data contain no labels and the machine learning algorithm is tasked with finding structure in the data.
One very common type of unsupervised learning is known as clustering and is used to for categorisation of google news. Each day, google algorithms crawl the web for news stories and use clustering algorithms to group similar stories together. Other pertinent examples of clustering include: organising computer clusters, social network analysis and market segmentation.
There are a number of other unsupervised learning algorithms and indeed a number of other types of machine learning than we have not touched upon in this post. If you’ve found this page interesting and have been inspired to leaner more, I recommend the following books:
- Pattern Recognition and Machine Learning by Christopher Bishop.
- Machine Learning: A Probabilistic Perspective by Kevin Murphy.
- Machine Learning: An Algorithmic Perspective by Stephen Marshland.
Also, for some great advice on the practical application of machine learning methods as well as a detailed derivation of some common algorithms, I strongly recommend Andrew Ng’s Coursera course .
Though it is true that the machine intelligence and learning capabalities are growing, what could be the major set back for this? For example, I am a secretary that needs to go through roughly all the emails my boss have, it is possible that I miss out one email because it was directed to spam by the machine. What could’ve prevented the machine from having this scenario?
Pingback: Predicting Stock Prices with Machine Learning - Introduction