This is an extract from a draft version of my PhD thesis:
“…For many years, the majority of the worlds financial markets have been driven by a style of auction, very similar to the basic process of haggling, known as the continuous double auction (CDA). In a CDA a seller may announce an offer or accept a bid at any time and a buyer may announce a bid or accept an offer at any time. This continuous and asynchronous process does away with any need for a centralised auctioneer, but does need a system for recording bids and offers and clearing trades. In modern financial markets, this function is performed by a uniform trading protocol known as the limit order book (LOB), whose universal adoption was a major factor in the transformation of financial exchanges.
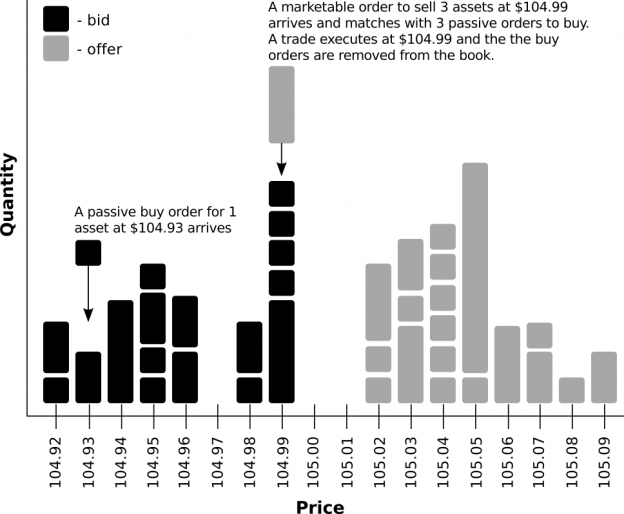
The most common type of order submitted to a LOB is the limit order – an instruction to buy or sell a given quantity of an asset, that species a limit (worst acceptable) price which cannot be surpassed. Upon receiving a limit order, the exchange’s matching engine compares the order’s price and quantity with opposing orders from the book. If there is is a book order that matches the incoming order then a trade is executed. The new order is termed aggressive (or marketable) because it initiated the trade, while the existing order from the book is deemed passive. If, on the other hand, the there are no matches for the incoming order it is placed in the book along with the other unmatched orders, waiting for an opposing aggressive order to arrive (or until it is cancelled). A visualisation of the structure and mechanism of a LOB is given in Figure 1.1.
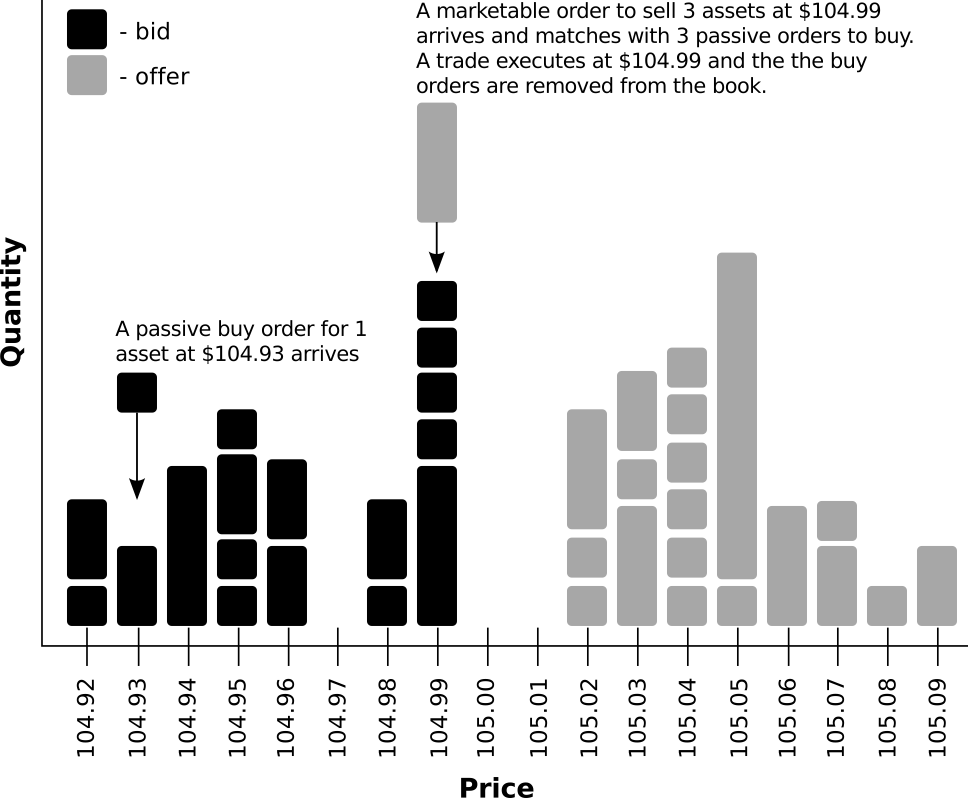
Figure 1.1: An illustration of LOB structure and dynamics.
The details of oder matching vary across exchanges and assets classes. However, most modern equity markets operate using a price-time priority protocol. That is, the lowest offers and highest bids are considered first, while orders of the same price are differentiated by the time they arrive (with priority given to orders that arrive first). Thus, limit orders with identical prices form a �first-in �first-out (FIFO) queues.
Most LOB-driven exchanges offer many more order types than the simple limit order. Another particularly common order type is the market order, which ensures a trade executes immediately at the best available price for a given quantity. As a result, market orders demand liquidity and risk uncertainty. Many more order types are available that allow control over whether an order may be partially �filled, when an order should become active and how visible the order is. Such order types include: conditional orders, hybrid orders, iceberg orders, stop orders and pegged orders, but the intricacies of these order types are beyond the scope of this report.
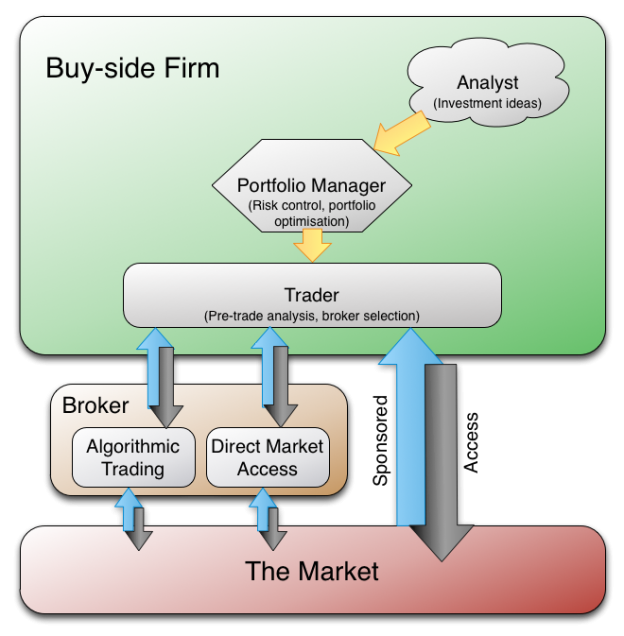
Traders interact with a screen-based LOB that summarises all of the “live” (outstanding)
bid and offers that have not yet been cancelled or matched. The LOB has two sides: the
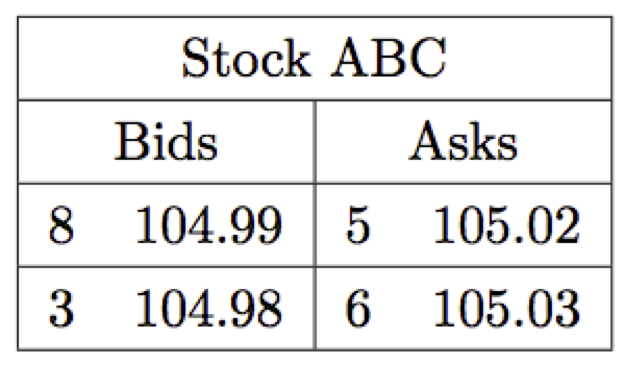
ask book and the bid book. The ask book contains the prices of all outstanding asks, along with the quantity available at each price level, in ascending order. The bid book, on the other hand shows the corresponding information for bids but in descending order; this way traders see the “best” prices at the top of both books. A� simplified example of what a trader may see when looking at a LOB is given below.
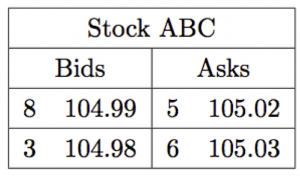
A simplified example of how a trader would view the LOB shown in Figure 1.1.
The amount of information available about the LOB at any given time depends on the needs and resources of the traders. Usually the only information that is publicly available (in real time) is the last traded price or the mid-price (the point between the current best prices). Professional traders may chose to subscribe to receive information on the price and size for the best prices, along with the price and size of the last recorded transaction, of an asset of interest; this is known as “level 1” market data. The most informative information, “level 2” or “market depth” data, includes the complete contents of the book (except for certain types of hidden orders) but this comes at a premium. For individual subscribers, the current cost of receiving real time level 2 data for equities from just the New York Stock Exchange (NYSE) exchange is $5000/month.
At �first glance, the rules or limit order trading seem simple but trading in a LOB is a highly complex optimisation problem. Traders may submit buy and/or sell orders at different times, prices, quantities and – in today’s highly fragmented markets – often to multiple order books. Order may also be modi�ed or cancelled at any time. The complexity of LOB strategies presents significant challenges for those attempting to model, understand and predicts behaviours. Nonetheless, the well-de�ned framework and the vast volumes of data generated by the use of LOBs presents an exciting and value opportunity for computational modeling…”